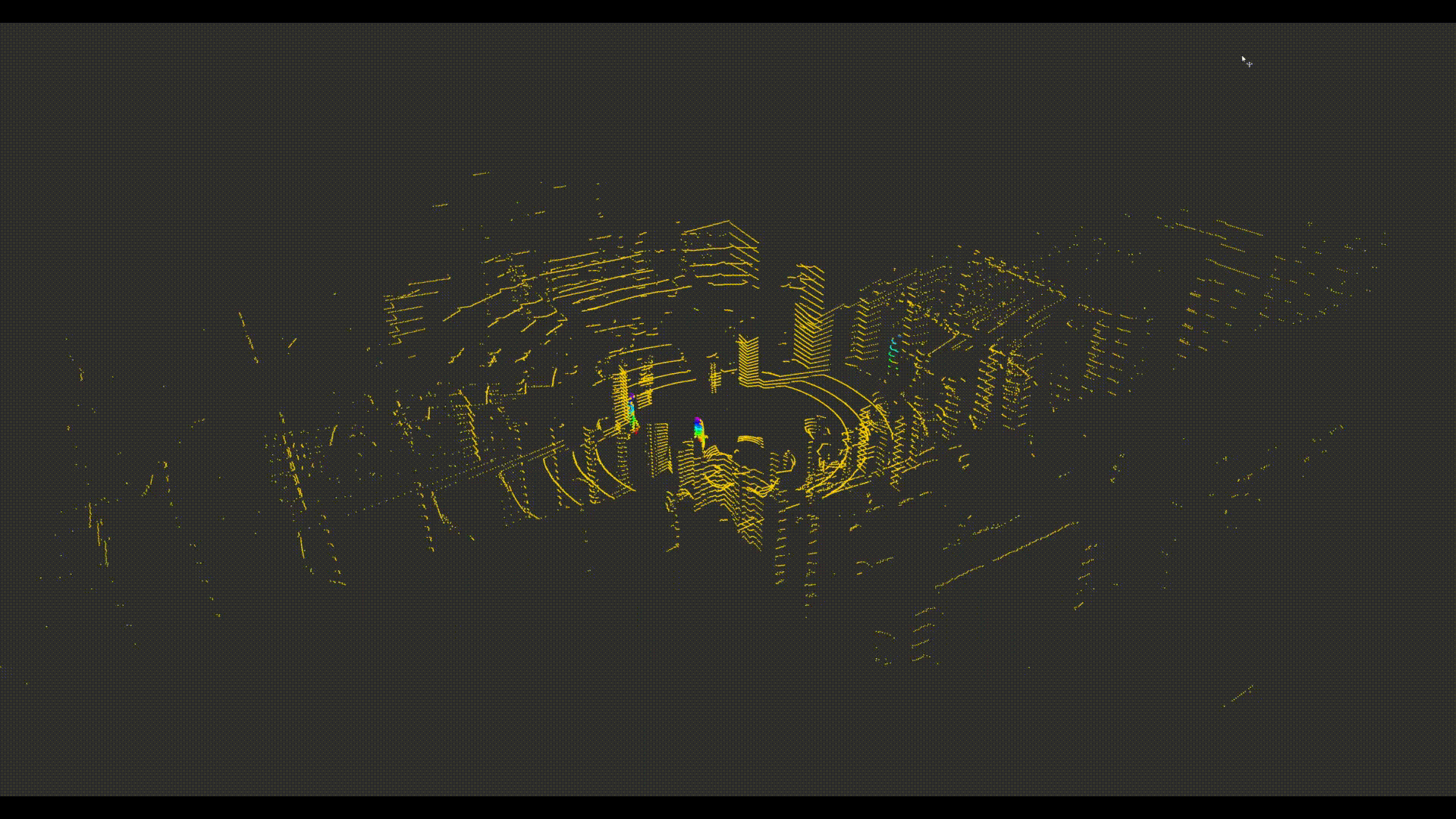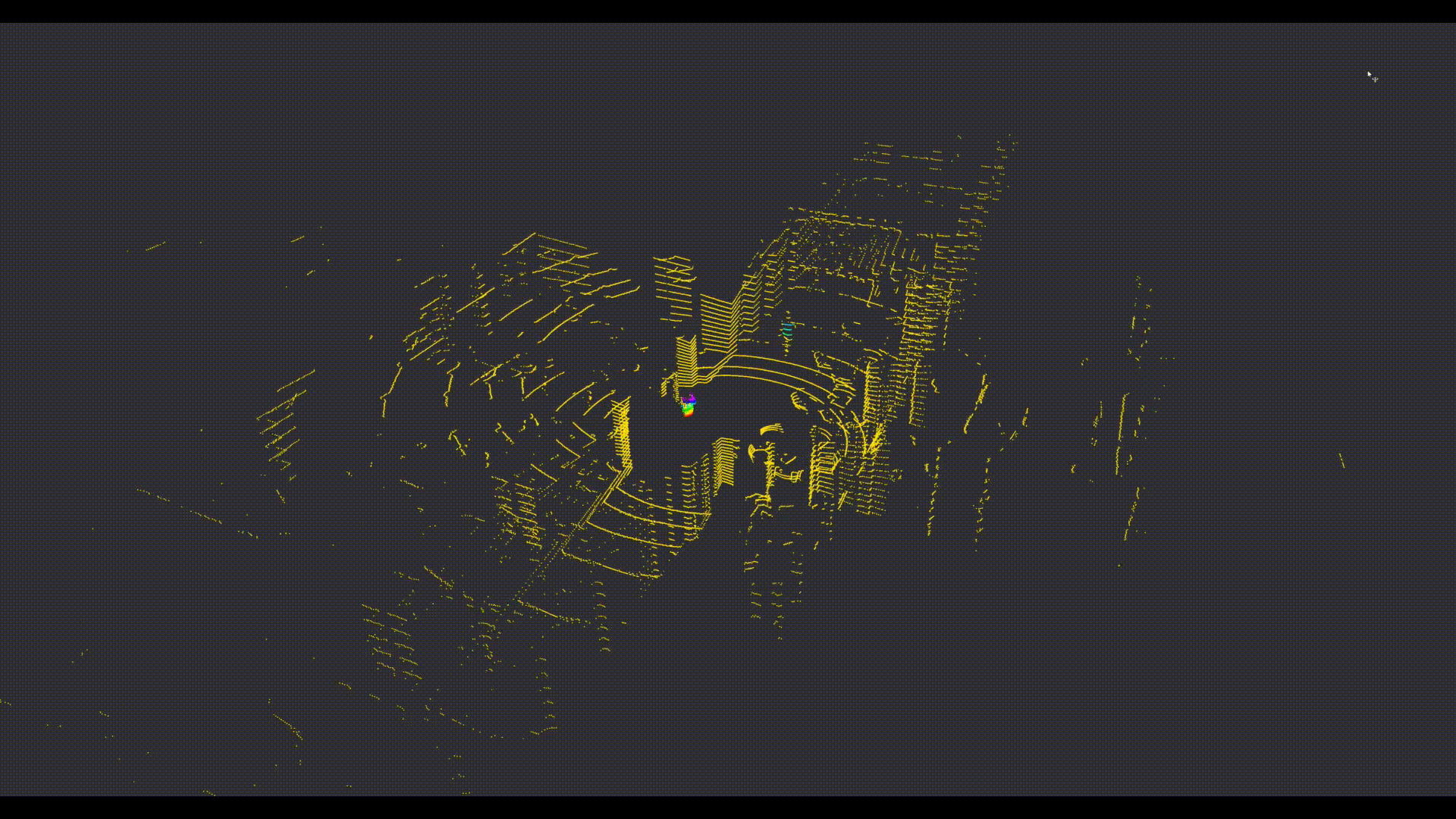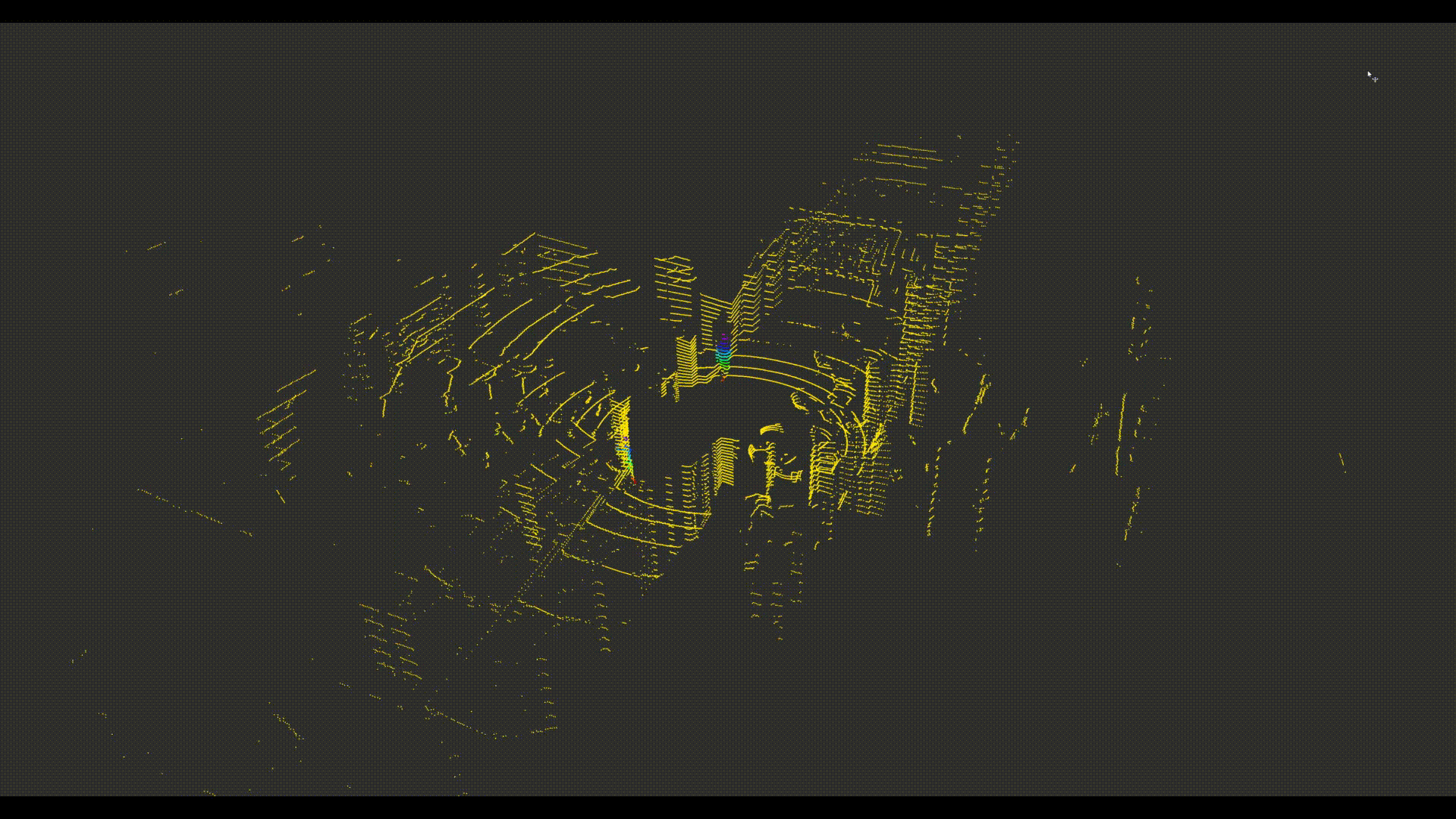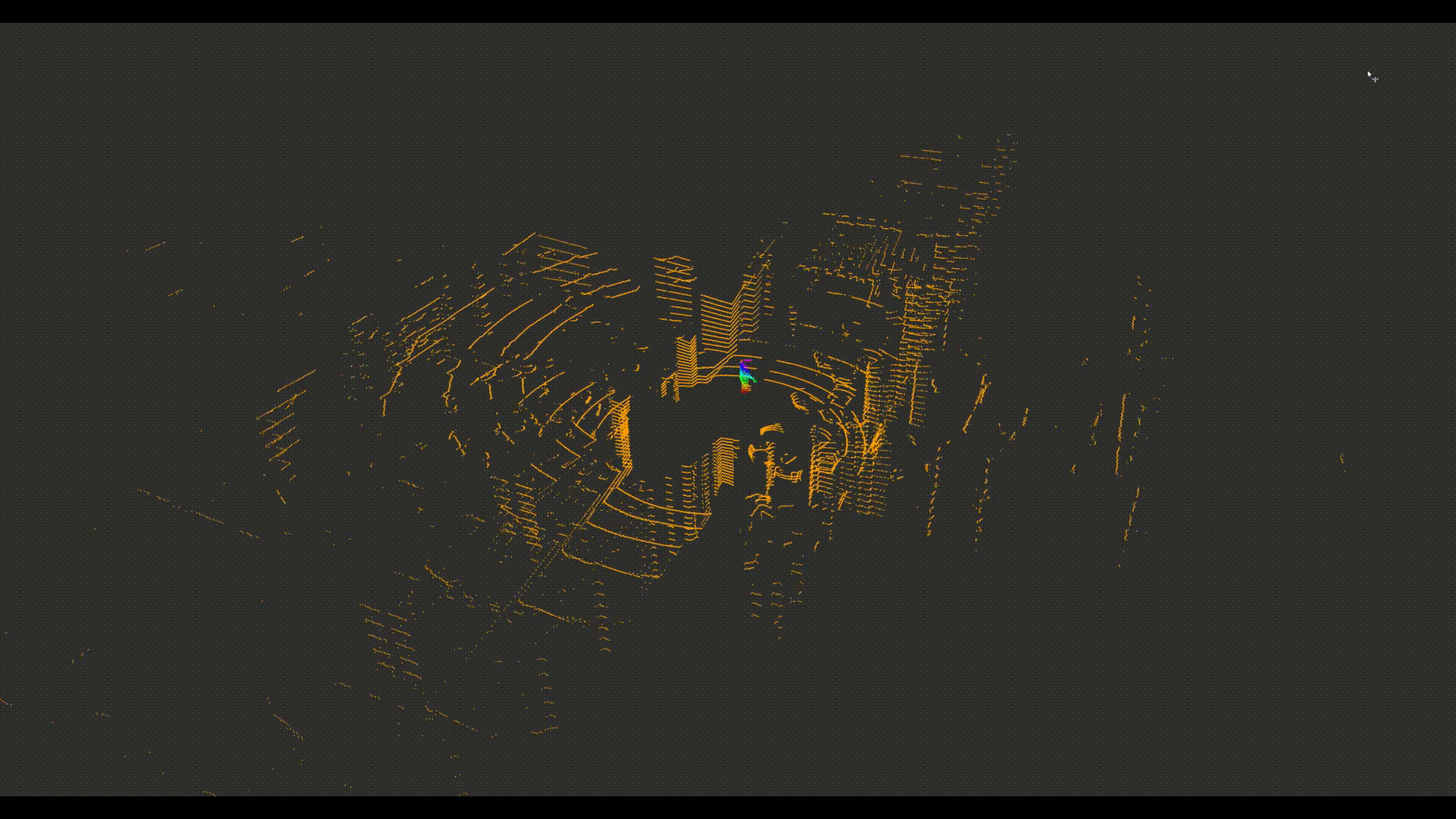





The BigRedLiDAR Dataset
We present a new large-scale dataset that contains a diverse set of point clouds sequences recorded in indoor scenes from 6 different places, with high quality point-level annotations of 28, 000 frames with multiple levels of complexities. The dataset is thus an order of magnitude larger than similar previous attempts. Details on examples of our annotations are available at this webpage.
Main features:
- 6 indoor scenes across Cornell University.
- Multiple levels of perception complexity.
- Hierachical estimation for moving objects.
- 28, 000 frames of 3D point clouds sequences.
- Precise point-wise annotation rather than box-level annotation.
The BigRedLiDAR Dataset is intended for
- Assessing the performance of learning algorithms for two major tasks of semantic indoor scene understanding: point-level and instance-level semantic labeling.
- Supporting research that aims to exploit large volumes of annotated point cloud data, like training deep neural networks.